
Production-Grade Multi-Tenant FastAPI RAG Engine
The Engineering Challenge: To build a production-grade, multi-tenant RAG system with full user isolation, secure authentication, and a highly concurrent pipeline — all without relying on heavy abstraction layers like LangChain. The goal was to prove that first-principles engineering with raw async Python, strict data contracts, and real database testing yields a faster, more maintainable, and fully verifiable AI backend.
Core Architecture:
- Authentication & Multi-Tenancy: OAuth2 Password Bearer with JWT access tokens and bcrypt password hashing. OTP-based email verification via async SMTP (aiosmtplib) for registration and password reset. Every document and vector is scoped to a user_id — queries are isolated at the database level.
- Document Ingestion: SHA-256 file fingerprinting for deduplication, non-blocking PyMuPDF parsing offloaded via asyncio.to_thread, zero-dependency O(N) sliding-window chunking that snaps to natural punctuation boundaries, and bulk insert via asyncpg.executemany over binary protocol.
- Retrieval & Generation: HNSW vector search with cosine similarity via pgvector (<=> operator), grounded system prompts constraining the LLM to provided context, and token-by-token streaming via StreamingResponse.
- Observability: structlog JSON logging with rotating file handler and optional Better Stack cloud aggregation.
Key Technical Implementations:
- Secure Authentication & Multi-Tenancy: Complete auth system with JWT access tokens (PyJWT), bcrypt password hashing, and OTP-based email verification for both registration and password reset flows — all fully async.
- Zero-Blocking Document Ingestion: CPU-bound PyMuPDF C-extension execution offloaded to background thread pools (asyncio.to_thread), safeguarding the event loop during massive file uploads.
- Pure Python Semantic Chunking: Custom O(N) sliding-window text chunker that snaps to natural punctuation boundaries, preserving semantic meaning without third-party ML orchestration libraries.
- Cryptographic Deduplication: SHA-256 fingerprinting on incoming document byte streams instantly rejects duplicate files, saving GPU embedding compute and preventing vector database bloat.
- Lightning-Fast Vector Search & Streaming: HNSW indexing and cosine distance (<=>) in Postgres for millisecond retrieval. Retrieved chunks are compiled into a grounded system prompt, and the LLM response is streamed token-by-token directly to the client.
- Enterprise Observability: structlog JSON logging with rotating file handler, asynchronously piped into Better Stack for real-time cloud log aggregation.
- Exhaustive Test Suite: 468 tests across unit, integration, and API route layers achieving 100% line coverage. Integration tests run against real ephemeral pgvector containers in CI — no mocking SQL.
- CI/CD Pipeline: GitHub Actions enforcing Ruff lint + format gates before running the full test suite against a real database.
What This Solved:
- Framework Bloat: Eliminated the overhead, latency, and unpredictability of high-level wrappers (LangChain/LlamaIndex) to gain total, deterministic control over the execution flow.
- AI Infrastructure Latency: Drastically reduced perceived user latency from ~15 seconds down to sub-second levels via asynchronous HTTP streaming and highly optimized database connection pooling.
- Security & Isolation: Full ownership of auth flows (no vendor lock-in), with per-user data isolation ensuring no cross-tenant data leakage.
- Confidence in Production: 100% test coverage with real database integration tests eliminates entire classes of bugs that mocked tests would miss.
Tech Stack: Python 3.12+, FastAPI, Uvicorn, PostgreSQL 16 (Neon), pgvector, asyncpg, Ollama, httpx, PyJWT, bcrypt, aiosmtplib, PyMuPDF, Pydantic v2, pydantic-settings, Docker, GitHub Actions, pytest, pytest-asyncio, pytest-cov, structlog, Better Stack, uv.
![]()
System Architecture:
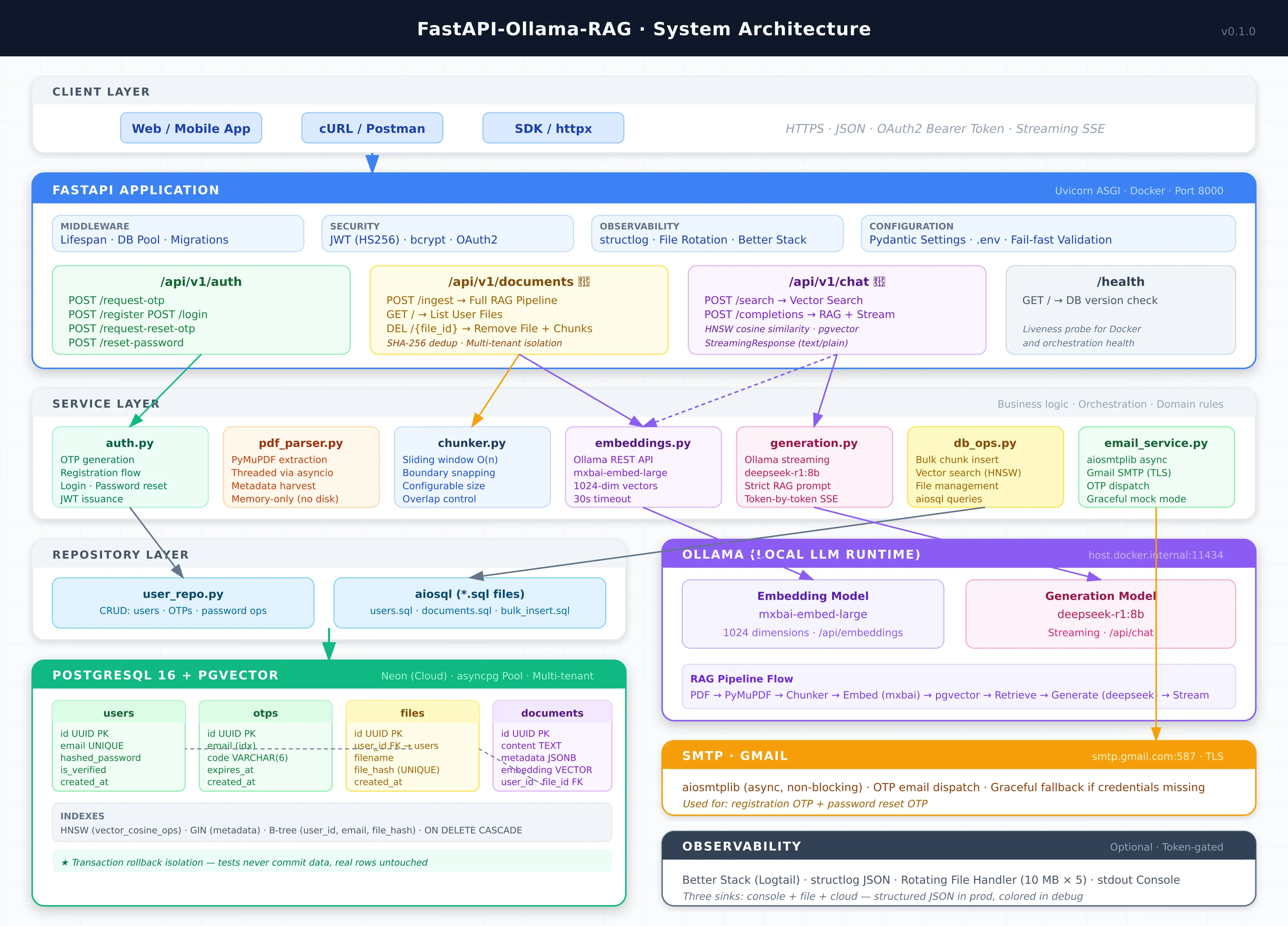
Figure: System architecture of the Production-Grade Multi-Tenant FastAPI RAG Engine.